
As organizations contend with the relentless evolution of AI-driven web scraping, the real challenge extends far beyond basic visibility and monetization. Effective defense now requires a nuanced understanding of how both good and malicious bots operate—and the inherent limitations of current solutions that still struggle to effectively distinguish between them.
Good intentions, flawed assumptions
Blocking bots like GPTBot, CCBot, and ClaudeBot, or implementing pay-per-crawl models, are positive steps that address the rights of content creators. However, these approaches rely heavily on bots voluntarily identifying themselves and respecting restrictions—a process that is fundamentally weakened by the absence of any compliance requirement mandating AI bots to self-identify. Many of the most problematic bots conceal their identity, circumventing detection and ignoring pseudo-compliance measures. The increasing presence of AI bots that scrape massive volumes of content will make it even more difficult to detect the most evasive noncompliant bot traffic.
The evasive majority: Rising to the challenge
Research shows that nearly half of evasive bots can bypass even advanced fingerprinting defenses (Measurement and Analysis of Fingerprint Inconsistencies in Evasive Bot Traffic - arXiv). When access restrictions tighten, compliance with robots.txt —the web standard that signals which parts of a website can be crawled—drops dramatically (Scrapers selectively respect robots.txt directives - arXiv), as noncompliant bots simply disregard these rules.
While robots.txt was originally established as an honor system to guide ethical web crawling, its effectiveness relies entirely on the willingness of bots to comply. For cooperative search engines and legitimate crawlers, robots.txt remains a valuable tool for managing access. However, in the escalating battle against evasive AI scrapers, its influence is increasingly limited, as malicious or profit-driven bots view these directives as optional, not mandatory, and routinely bypass them in pursuit of scraping valuable content.
As traditional web defenses improve, attackers increasingly target APIs and structured data, which often lack robust monitoring and hold increasingly valuable information. The 2025 Advanced Persistent Bots Report by F5 Labs highlights that much of today’s automated traffic now focuses on mobile APIs and structured endpoints, particularly in sensitive sectors like finance, retail, and travel. These sophisticated bots use header spoofing, rapid IP rotation, and mimic human browsing patterns to avoid detection.
Detection as foundation: The path forward
Traditional defenses such as blocklists are no longer enough against advanced, evasive bots. Modern bot management defenses must center on detection: analyzing behavioral signals to spot intent, identifying headless browsers and proxies, applying dynamic device fingerprinting, and vigilantly monitoring vulnerable API endpoints. In this new landscape, detection is not just an added feature but the essential core of any effective protection strategy.
F5’s approach to managing bots
F5 Distributed Cloud Bot Defense is grounded in the belief that true web protection begins with unparalleled visibility. Rather than merely erecting paywalls or blocking known bad actors, F5’s philosophy is to illuminate the full spectrum of automated activity—empowering organizations to see not only legitimate bot traffic, but also the vast majority of evasive, noncompliant bot traffic that persists despite the various countermeasures that organizations have in place.
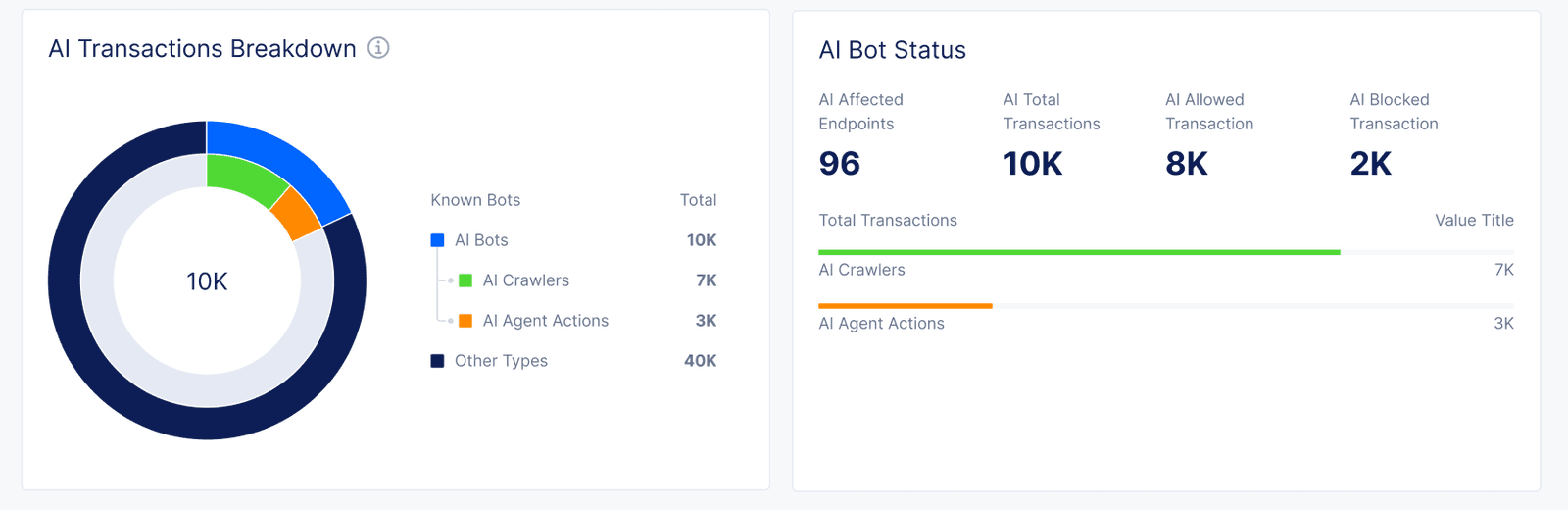
Upcoming F5 capabilities providing visibility to AI-driven transactions
F5’s strategy builds on a suite of dynamic detection technologies: behavioral analysis to differentiate between human and automated traffic; identification of headless browsers and proxy usage; and adaptive fingerprinting that evolves alongside attacker tactics. F5 continuously monitors API and structured data endpoints, where high-value attacks increasingly occur, ensuring that even the stealthiest bots are brought into view. The result is actionable visibility—not just for security teams, but for compliance, monetization, and ongoing control. With F5, organizations gain the clarity they need to make informed decisions and protect their digital assets in a rapidly changing threat landscape.
Conclusion: Visibility first, everything else follows
As the ecosystem of automated threats grows more sophisticated, it’s essential to move beyond conventional defenses and embrace a proactive approach grounded in real-time detection.
Book a demo to see our detection in action. Compare live results, review anonymized logs, and let your teams test our solution’s effectiveness. Take the next step toward real visibility and discover how clarity strengthens your defenses.
About the Author

Related Blog Posts

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

F5 joins the Dell AI Ecosystem Program to help enterprises operationalize AI
F5 joins the Dell AI Ecosystem Program to help enterprises deploy production AI with greater performance, security, and control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.