
In today’s AI era, data is the lifeblood powering complex model training, fine-tuning, and inferencing. However, the process of ingesting vast amounts of data stored in S3 deployments often presents significant hurdles. Organizations face a relentless influx of data across multiple locations and performance tiers, resulting in bottlenecks that diminish overall training efficiency and slow innovation. Without a robust data ingestion strategy, even the most sophisticated AI systems risk delays based on inefficient data ingestion, ultimately impacting time-to-insight and competitive positioning.
The specific challenges in managing AI data are not solely based on data volume, but also the need for seamless access, high-speed replication, and consistent load balancing across diverse infrastructure environments. Existing approaches can falter when faced with multi-zone, multi-cluster deployments, or when reconciling cost-effective storage with high-performance demands. This creates a scenario where operational teams are forced to decide between cost savings and performance—an unsustainable compromise when rapid, reliable data movement is critical for AI workflows.
What is AI model training?
AI model training is the process of teaching algorithms to recognize patterns and make decisions by exposing them to rigorously curated datasets. It involves iterative refinement where models learn from data, adjust their internal parameters, and improve predictive accuracy. This disciplined approach bridges raw data with actionable insights, enabling sophisticated decision-making and transformative innovation.
Increasing your AI training pipeline
F5 BIG-IP Local Traffic Manager (LTM) and F5 BIG-IP DNS address these challenges by increasing AI training pipelines with advanced load balancing and enabling data replication capabilities to ensure high-speed, resilient access to S3-stored data. By replicating datasets from less costly storage systems to high-performance tier 1 setups, F5 empowers organizations to simultaneously optimize costs and accelerate AI model training. This solution mitigates the risk of data processing bottlenecks and guarantees that every byte of data is delivered with the precision needed for iterative training and inference, dramatically enhancing overall operational throughput.
High reliability, seamless integration
At the heart of F5’s offering is a commitment to unbreakable reliability through seamless integration with leading storage vendors and Kubernetes-native orchestration platforms. BIG-IP LTM and BIG-IP DNS utilize hardware-accelerated networking to efficiently handle high-throughput demands and implement dynamic replication strategies, seamlessly adapting to the evolving requirements of AI infrastructures. These capabilities are powered by F5 rSeries and F5 VELOS purpose-built hardware for high-performance scalability. These capabilities ensure that multi-region, multi-zone deployments maintain consistent performance, allowing complex AI pipelines to function without interruption. By harmonizing diverse storage ecosystems within a single orchestrated framework, F5 creates an infrastructure that is as versatile as it is powerful.
Security and scale at the forefront
Beyond performance and integration, security and scalability are integral to S3 load balancing and replication solutions. Advanced security mechanisms protect data in transit and at rest—vital for organizations that must adhere to rigorous regulatory standards. With tailored support for NetOps, MLOps, and DevOps teams, F5 BIG-IP Advanced Firewall Manager (AFM) not only delivers robust performance but also ensures data used for AI training and fine-tuning remains secure and compliant. This holistic approach addresses the complexities of AI infrastructure management by combining state-of-the-art security features with scalability solutions that grow alongside organizational demands.
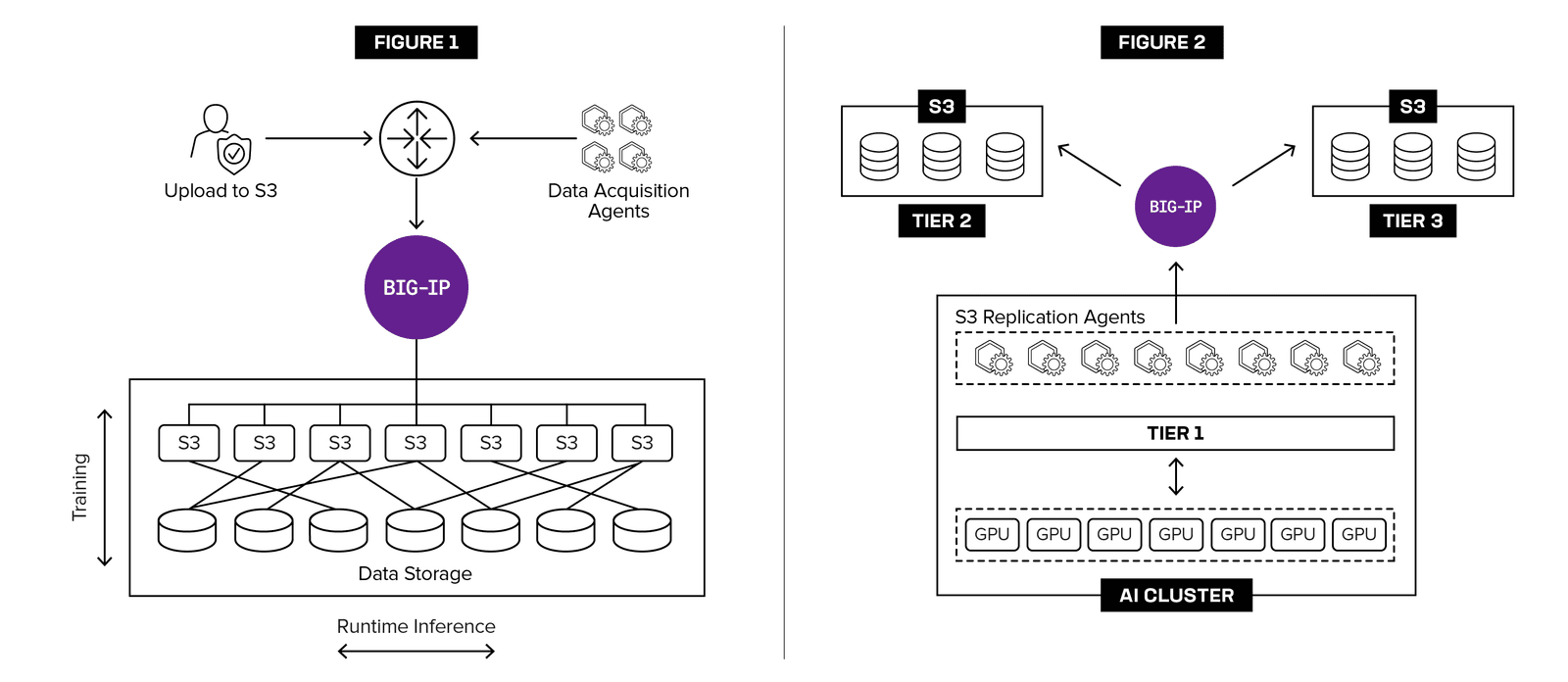
Figure 1: Enable secure, resilient, and high-performance load balancing to optimally route AI data across systems, ensuring rapid processing and uninterrupted availability for AI data ingestion across S3 storage deployments.
Figure 2: Replication to cost-efficient, lower-performance Tier 2 and Tier 3 storage repositories from high-performance Tier 1 infrastructure is commonly orchestrated via the S3 protocol to maintain both scalability and performance.
Maximizing ROI and preparing for tomorrow’s AI workloads
With advanced load balancing and data replication, the integration of S3 and BIG-IP provides a comprehensive solution for the pressing challenges in AI data management. Customers can optimize data access speeds and seamlessly enforce robust security practices across integrated, heterogeneous environments—maximizing ROI while future-proofing their AI infrastructures. As AI infrastructure continues to evolve, F5 stands at the forefront, ensuring data pipelines remain agile, reliable, and secure, ready to power the next wave of AI breakthroughs.
To explore how F5 BIG-IP LTM, BIG-IP DNS, BIG-IP AFM and F5 hardware systems can support your S3 data ingestion and replication requirements for AI model training and fine-tuning, contact us to connect with your F5 account team, or download our solution overview.
F5’s focus on AI doesn’t stop here—explore how F5 secures and delivers AI apps everywhere.
About the Author

Related Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.