
The need for scalability isn’t even a question these days. The answer is always yes, you need it. Business growth depends on operational growth of the applications that are, after all, part and parcel of today’s business models – no matter what the industry. So it is that systems are generally deployed with the things necessary to achieve that scale when – not if – it will be needed. That usually means a proxy. And the proxies responsible for scale (usually a load balancer) are, therefore, pretty critical components in any modern architecture.
It’s not just that these proxies serve as the mechanism for scaling; it’s that they’re increasingly enjoined to do so automagically through the wonders of auto-scale. That simple, hyphenated word implies a lot; such as the ability to instruct, programmatically, a system to not only launch additional capacity but also make sure the proxy responsible for scalability knows of its existence and is able to direct requests to it.
One assumes any proxy worth its salt has the programmatic interfaces required. The API economy isn’t just about sharing between apps and people, after all, it’s also about sharing between systems – on-premises and off, in the cloud. But what we often fail to recognize is that the task of adding a new resource to a load balancing proxy takes place on the management or control plane, not on the data plane.
That makes sense. We don’t want to be interfering with the running of the system while we’re gathering statistics or manipulating its configuration. That’s a no-no, especially in a situation where we’re trying to add capacity because the system is running full boar, delivering apps to eager users.
But what happens when the reverse occurs? When the running of the system interferes with the ability to manage the system?
Your auto-scaling (or manual scaling, for that matter) is going to fail. Which means app capacity isn’t going to increase, and the business is going to suffer.
That’s bad, as if you needed me to tell you that.
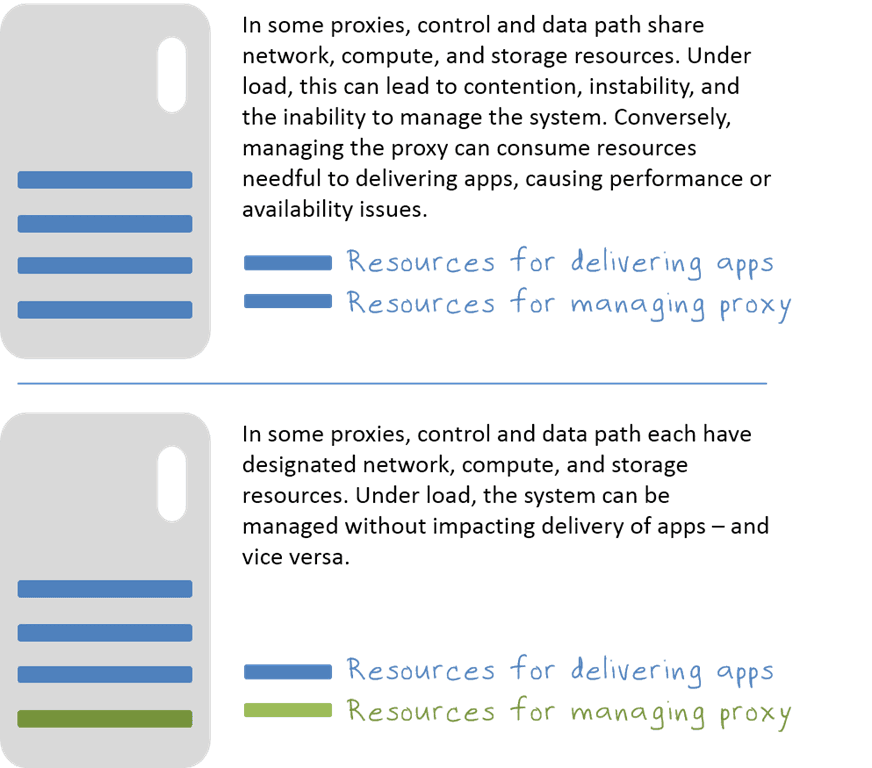
The reason this happens is because many proxies (which were not built with this paradox in mind) share system resources for both control and data planes. There is no isolation between them. The same network that delivers the apps is used to manage the proxy. The same RAM and compute assigned to deliver apps is assigned to manage the proxy. Under load, only one of these two gets the resources. If you’re trying to add app resources to the proxy in order to scale and you can’t access the system to do it, you’re pretty much in trouble.
That’s why it’s important to evaluate your choice of proxies with an eye toward manageability. Not just its ease of manageability. Not just its API and scripting capabilities, but its manageability under load. Proxies that have been specifically designed for massive scale should have a separate set of resources designated as “management” resources to ensure that no matter how loaded the data plane is with delivering apps, it can still be managed and monitored.
In the network world we call this out of band management, because it occurs outside the data path – the primary path; the critical path.
The ability to manage a proxy under load, out of band, is important in the overall ability to scale – automagically or manually – the apps and, through them, the business.
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.