
This blog is a follow-on to “What is a good control plane to operate a large number of Kubernetes clusters”. The previous blog described Volterra’s unique Fleet Operations approach to managing a fleet of infrastructure sites and applications. This specific blog describes a key challenge of configuration drift faced by an operations team when making configuration changes across a large number of clusters or sites. I call this challenge, “Time to Effect.”
What is Time-to-Effect?
It can simply be described as how long does it take for an operation’s intent to take effect. Examples include:
- How long will it take for my security policy configuration to take effect on all my sites?
- How long will it take for the latest version of my application to be propagated to all sites?
- How long will it take to upgrade the operating system or infrastructure software on all my globally distributed sites?
Why is it important?
This question can be answered through a few real-world customer examples:
- Meltdown and Spectre — Top of mind for every CISO after the Meltdown/Spectre news broke was how to patch the operating system on all their infrastructure quickly. The operations team was being measured hourly on time for their intent (i.e., upgrade OS version) to take effect.
- You must have heard about the fleet of vending machines that caused a denial of service attack on a university? Here is the TL;DR in case you did not follow that attack - hackers exploited a zero-day vulnerability and installed malware that connected with other vending machines and created a fleet of vending bots. It then sent huge volumes of traffic and caused a denial of service attack on the university. The university upon detecting the attack had to configure network policy rules on each vending machine one by one to prevent access to the command & control server. It was extremely important to them to have their intent (i.e., block access to a specific website) be effective immediately on all vending machines to stop the bleeding.
Time to Effect is important for multiple categories such as infrastructure software, application software, network policy, and security policy.
What is the challenge?
The severity of the challenge is experienced most when the operations team have to manage
- A large scale of sites
- Globally distributed sites
- Heterogeneous environments i.e., sites in private, public, telco clouds and edge devices
- Inconsistent connectivity for sites
A great example of such an operations team of an automotive OEM responsible for updating the software and managing the connectivity of their automobiles (hereafter referred to as customer sites). The typical deployment would include a private data center wherefrom the operations team controls their automobiles globally (or regionally depending upon the organizational structure).
To understand the challenge, let’s look at the solutions the operations team have at their disposal. Most solutions offer management software hosted in a customers’ private data center to centrally manage the large scale of distributed sites. When the automotive OEM configures a policy that needs to be applied to all the automobiles, the central management software would essentially download a configuration script to each car one by one. The configuration script could be an ansible playbook or helm chart that executes a series of configuration commands on each site. This can be visualized as shown in the diagram below.

The problem is that Time to Effect is directly proportional to the number of sites. Centralized management software vendors will argue that as long as all operations can be performed remotely and in an automated fashion, this is the best that can be achieved.
Volterra begs to disagree and we can prove it in this blog. We have built a distributed control plane with a hierarchical, scale-out architectural approach that is designed to ensure minimal Time to Effect.
Volterra Architecture for Minimal Time to Effect
The fundamental building blocks to achieve minimal Time to Effect are:
- Hierarchical tree-based architecture
- Purpose-built distributed control plane
A high-level architectural overview is shown next.

Volterra’s hierarchical architecture approach is to create a tree of nodes for configuration distribution. Each node does a store and forward — i.e., stores the configuration locally and then forwards to its children. This can best be described with an example. When a user configures an object such as network policy, on the Volterra Console, the control and management plane distributes the configuration to immediate children, the Regional Edges (RE). Each RE does a store of configuration locally and forwards to its children. RE’s children are customer sites connected to that RE.
A hierarchical tree-based architecture ensures minimal Time to Effect. The Time to Effect is bounded by the number of levels in the tree and the number of children per node. The maximum number of levels in the tree is three (controller → RE →customer site). The number of children per node is directly proportional to the number of sites connected to RE. A service instance is spawned on the RE to handle the configuration for a set of sites. Volterra’s scale-out control plane spawns new service instances, on-demand if there is an increase in the number of sites connected to the RE.
Test Setup
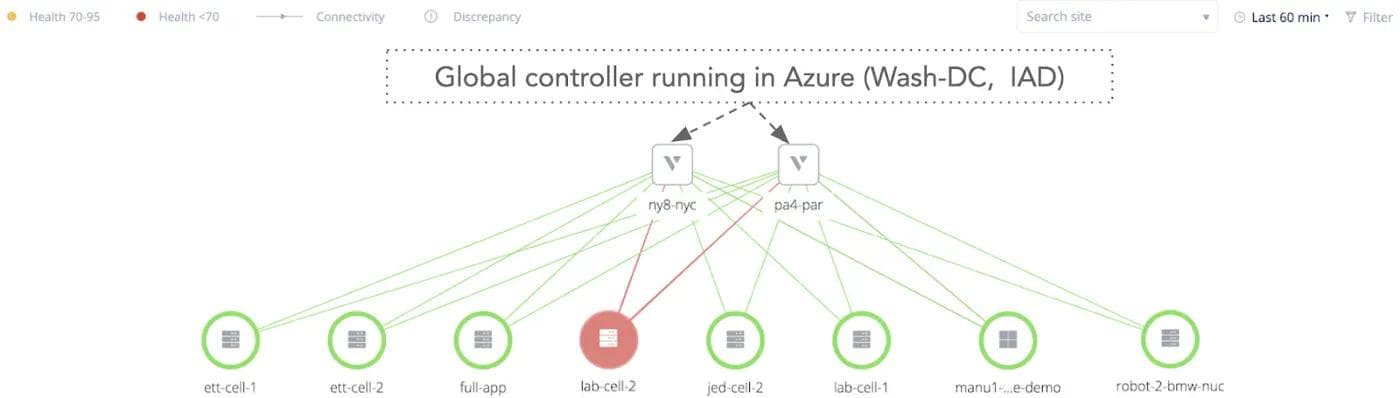
Time to Effect measurement was done on a high scale of customer sites connected to two Regional edges located in New York (NY8-NYC) and Paris (PA4-PAR). Customer sites were globally distributed across Santa Clara (CA), Houston (Texas), Madrid (Spain), Prague (Czech Republic), London (UK), etc. Also, customer sites were across heterogeneous environments such as AWS, Virtual Machines (ESXi), Edge Gateways including Intel NUCs and Fitlet2.
Volterra’s customer portal and global control plane were running in Azure (Washington-IAD). The customer sites were distributed across multiple namespaces and tenants to represent a real-world operating environment.
Failure conditions were simulated by killing service instances on the RE and using poor-quality connectivity links between RE and customer sites. A snapshot-in-time view of a segment of the entire fleet, in a single namespace, is shown in Figure 3.
Test Methodology
Audit logs, with timestamps, are captured in the Volterra system whenever objects are configured on the Volterra console and configuration is applied on each customer site. The propagation time was measured as the time difference between configuration on the portal to the application of the configuration on the customer site. A detailed step by step process is described next.
- Configure objects on the customer portal.
- Measure start time as the object creation time on the customer portal (referred to herein as the Volterra Global Controller. See figure 4 for example.
- Measure end time as the object creation time on the customer site. See figure 5 for example.
Note the screenshots shown are sampled and do not refer to the same measurement iteration.
Configuration Start Time

Configuration End Time

Test Results
The test results of the propagation times are shown in figures 6 and 7. The graph in figure 6 indicates that most of the measurement samples had a propagation time between 0–400ms. This means all customer sites get updated with a new configuration between 0–400ms. As mentioned earlier, failure conditions were simulated by restarting services on the RE and introducing connectivity failures/delays on the customer site. The configuration propagation time is longer in these failure conditions and ranged from 600ms to 9 seconds, in these specific tests, depending upon the failure type. For example, connectivity failure between RE and customer sites will increase the time for the configuration to reach the customer site. However, the benefit of Volterra’s distributed control plane is that it follows the paradigm of eventually consistent config, i.e., it keeps retrying to ensure the configuration on all customer sites is aligned to the intent defined by the customer.
")
The graph in figure 7 indicates that 85% of the time, all customer sites get updated with a new configuration within 322 milliseconds. In the situation when failure conditions are introduced, few customer sites could experience a propagation time of ~3–9 seconds.

Disclaimer: These measurements are closely tied to the topology, scale, deployment environment, and failure situations simulated. We did not measure all possible failure situations or other environments. Therefore we cannot make claims on the propagation delay in other situations or environments that were not tested. For example, if there is a Kubernetes cluster failure, the system would have to wait for failure detection, restart and retry of configuration, resulting in a higher propagation delay.
Related Blogs
About the Author
Related Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.