
Apps are under siege. Attacks occur with alarming frequency – every 39 seconds according to research conducted by the University of Maryland – with disturbingly high probability of success.
Developers, who increasingly shoulder the burden of securing these apps, are well-aware of the threat. A late 2017 survey of node.js developers by NodeSource and Sqreen found that “more than a third of all respondents (34 percent) believe there is a strong chance their organization will be the target of a large-scale attack in the next six months.” Given our own findings that the initial attack vector in 86% of attacks is either the application itself or identities, that belief is more than reasonable.
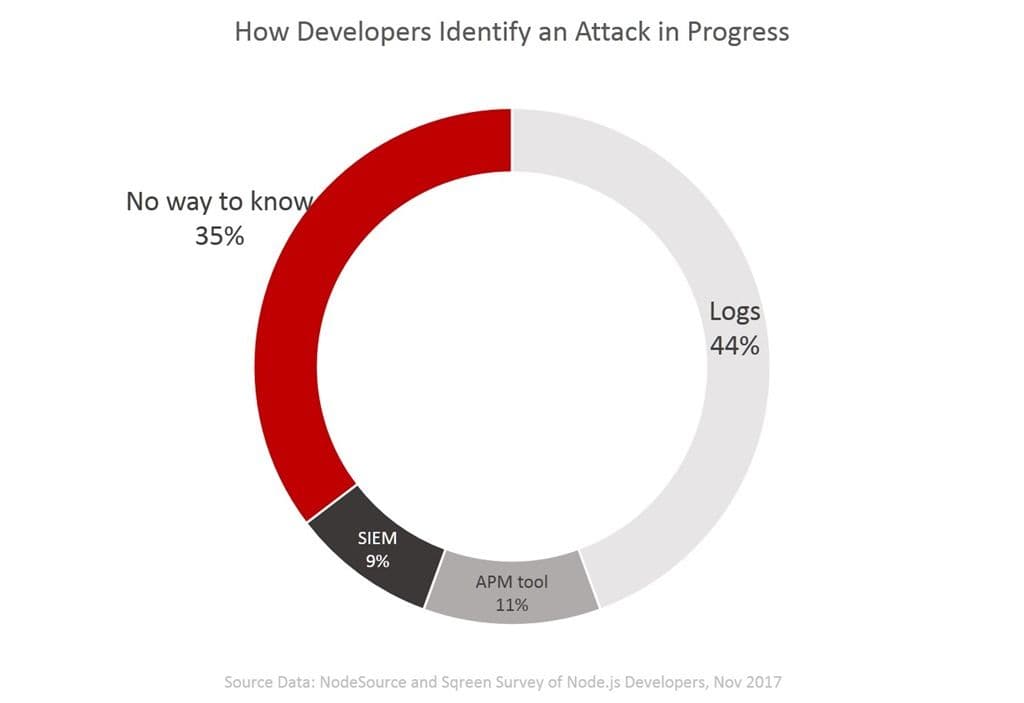
It might be disturbing to discover then, that “35% of respondents weren’t sure how to identify an attack as it’s happening.” They expect one, but they aren’t sure how to recognize it when it hits. If you aren’t sure how to identify an attack in progress, it’s passingly difficult to stop it.
That makes the 23% of Node.js developers (23 percent) that do not use any form of real-time protection against attacks even more troubling.
The good news is that based on our own research for the State of Application Delivery 2018, most organizations use some kind of real-time protection against attacks. Four in five use two or more technologies, including web application firewall (57%), runtime application self-protection (11%), and user behavior analytics (26%).
The characteristic all these technologies have in common is what developers are often lacking: visibility. Visibility is necessary because in order to detect (and hopefully identify) an attack, you must be able to recognize abnormal behavior.
Applications and their services have fairly predictable usage patterns. For example, single-sign on (SSO) applications tend to see heavy usage on Monday mornings and light usage on Friday afternoon. Financial applications tend to see heavy use just before financial events – paydays, tax-period endings, and fiscal year closings.
Even consumer-facing applications have predictable usage patterns that can be used to help detect unusual (and potentially dangerous) behavior. For example, in April 2017 Malauzai Software released one its monthly “little data” reports based on usage data collected from over “435 banks & credit unions, covering 13.2 million logins from 730,000 active Internet and Mobile Banking users.” In it, we learn that “100% of end-users see their balances and review recent transaction history. That is because balances and recent history show in the landing page for everyone to see. And this is why they come. 77% of the time. 77% of the time all a user does is check balances and history. Only 23% of the overall interactions in digital banking go beyond balances and history to perform some other task.”
You could infer, then, that a sudden interest in other types of transactions could be indicative of an attack.
Unfortunately, such statistics are not always readily available for every application. That’s why visibility (monitoring) is important, so you can establish a baseline against which anomalies become obvious. Not all anomalies are indicative of an attack, of course. A mid-week spike in SSO service usage might be because of a deadline to change corporate passwords, or because Monday and Tuesday were holidays and no one was in the office. Still, having a baseline gives you a leg up on identifying the behavior that can tell you an attack is in progress.
Make it a point to check out these three abnormal usage patterns in case they are, in fact, an attack. Because quite often – they are.
1. Dramatic Increase in Connections. Maybe you’ve just gone viral, but chances are there’s something else going on. When you see a significant spike in connection rates, it’s a good idea to immediately check to see if there is a corresponding increase in network traffic. If not, your Spidey senses should be tingling as that’s a potential attack. GET floods are the easiest of all HTTP-based DDoS attacks to perpetuate, because they rely on simply spraying a metric ton of HTTP GETs at an application and nothing else. They often don’t even try to access real URLs, because the point is merely to consume as many connections as possible and force you into an overload situation.
If the increase is specifically targeting URLs or services that provide logins you might be the victim of a brute force attack to gain access.
Look for server errors, increasingly degraded performance, and resource exhaustion as signs of an ongoing attack.
2. Size of Outbound Response. A suddenly large outgoing response can indicate a successful exfiltration attack in which the attacker has gained access to data they should not have. This is one of the primary red flags of a successful SQLi attack, as attackers often use wildcards to gain unauthorized access to data. You’d think SQLi is such a well-understood attack vector that by now we’d have this covered. But SQLi is consistently amongst the top successful attacks every year in a number of industry reports.
Basically, the attack is designed to circumvent restrictions on data access. So instead of receiving a single record (or even just a few) the attack might receive thousands. A successful attack, then, will be noticeable because the amount of data being returned will be significantly larger than the norm.
Any significant difference in response size should be enough to warrant immediate investigation.
3. Crashes and Fails. While these can be explained by defects or accidentally ‘bad’ input, they can also be indicative of attempts to overrun buffers in third-party libraries or web server platforms (or your application) in the hopes of exploiting a new (or old) vulnerability. While it’s nice that systems can just ‘restart’ themselves today, it’s not nice to ignore the reason they needed restarting.
While it might be tempting to ignore the occasional crash, don’t.
Don’t ignore crashes and faults and consider architectures that allow you to quarantine faulty systems until you can look them over.
This is not an all inclusive list, obviously, but it is a good start to being able to identify when an application might be under attack – and stopping it in its tracks.
Stay safe!
About the Author

Lori MacVittie is a Distinguished Engineer and Chief Evangelist in F5’s Office of the CTO with deep expertise in application delivery, automation strategy, and infrastructure. She is known for turning complexity into clarity whether she’s defining guardrails for AI agents, dissecting brittle multicloud architectures, or probing the limits of scalable systems. She brings more than thirty years of industry experience across application development, IT architecture, and network and systems operations. Before joining F5, she served as an award-winning technology editor. MacVittie holds an M.S. in Computer Science and is a prolific author whose publications span security, cloud, and enterprise architecture. She is also an avid tabletop and video gamer with unapologetically strong opinions about cheese.
More blogs by Lori Mac VittieRelated Blog Posts

A new path to technical excellence for F5 partners
Introducing F5 Partner Foundations, a structured learning curriculum to build F5 partner engineer expertise with a clear pathway to specialization.

Secure-by-design storage for agentic AI: Why runtime visibility plus traffic control matters
Learn how F5 is collaborating with NVIDIA to help protect agentic AI with secure-by-design AI infrastructure, runtime visibility, and traffic control.

Why sub-optimal application delivery architecture costs more than you think
Discover the hidden performance, security, and operational costs of sub‑optimal application delivery—and how modern architectures address them.

Architecting for AI: Secure, scalable, multicloud
Operationalize AI-era multicloud with F5 and Equinix. Explore scalable solutions for secure data flows, uniform policies, and governance across dynamic cloud environments.

AppViewX + F5: Automating and orchestrating app delivery
As an F5 ADSP Select partner, AppViewX works with F5 to deliver a centralized orchestration solution to manage app services across distributed environments.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.