
Modern Applications at a glance
Microservices are the norm in today’s software deployment world. As applications are decomposed into different services, the number of applications that an organization needs to deploy increases. Often the number of services increases hundreds or thousands of times. If I have one hundred applications today, this often becomes thousands of microservices.
The ultimate goal is to deliver applications and new functionality into the hands of end users and customers faster.
The challenge is how do I continuously deploy thousands of services without sacrificing deployment velocity.
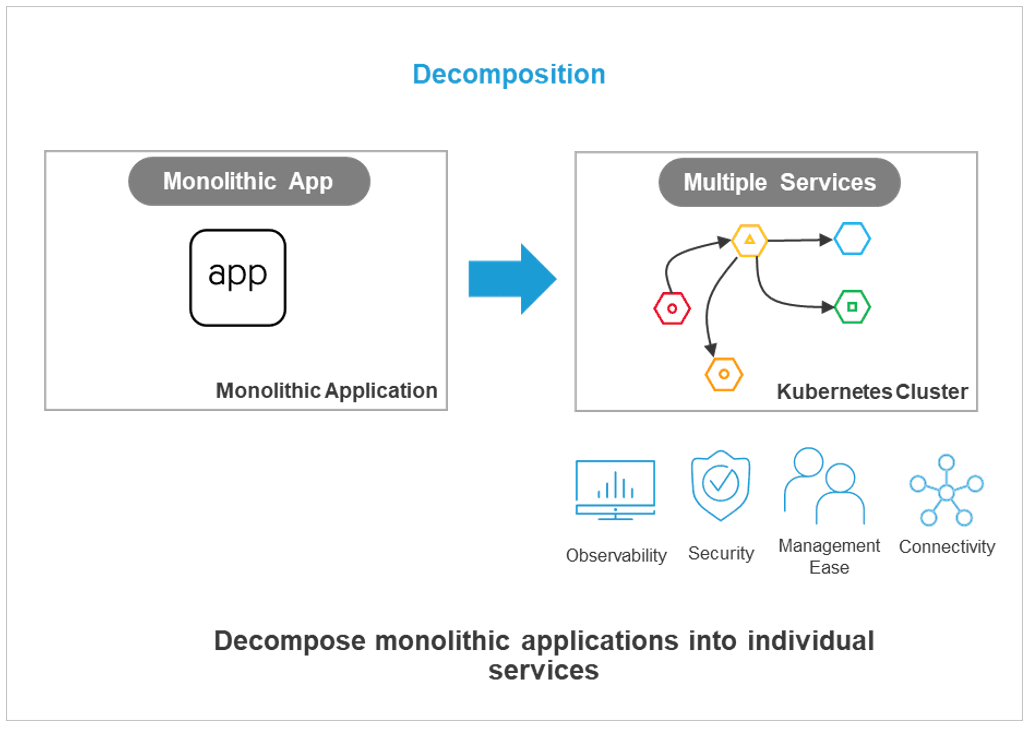
Today, part of the answer is to use Kubernetes for deployment. Kubernetes is the de-facto standard for deploying microservice based applications at scale. It gives you repeatability, scale and importantly deployment velocity—which means getting features to end users faster.
Organisations that scale their microservices deployments look to running multiple Kubernetes clusters. Often, these multiple clusters run in different locations. These locations can be branch or retail sites, different cloud providers or more often, a mixture of both.
The bigger you get the harder it is
Managing application deployment at speed and scale across multiple Kubernetes clusters is hard. Each application is now comprised of multiple services. There are multiple applications, services, sites and Kubernetes clusters to contend with.
Architecturally, this leads to complex build and deployment pipelines that are often bespoke to either a single cloud provider, or a single application. Bespoke also means brittle, fragile and a tendency to break, usually during the middle of an application deployment.
Deployment at scale
The ability to deploy multiple applications and services, across distributed locations is here now. This means that the ability to deploy your applications at speed across multiple Kubernetes clusters exists today. This capability leads to reduced deployment time and reduced complexity. Ultimately this means happier end users with new features in their hands faster.
As an application developer, I can treat multiple Kubernetes clusters as a single entity. This means that when I deploy an application to my single “virtual” Kubernetes cluster, that I am actually deploying my application across multiple clusters. These multiple clusters can be next to each other or on opposite sides of the world.
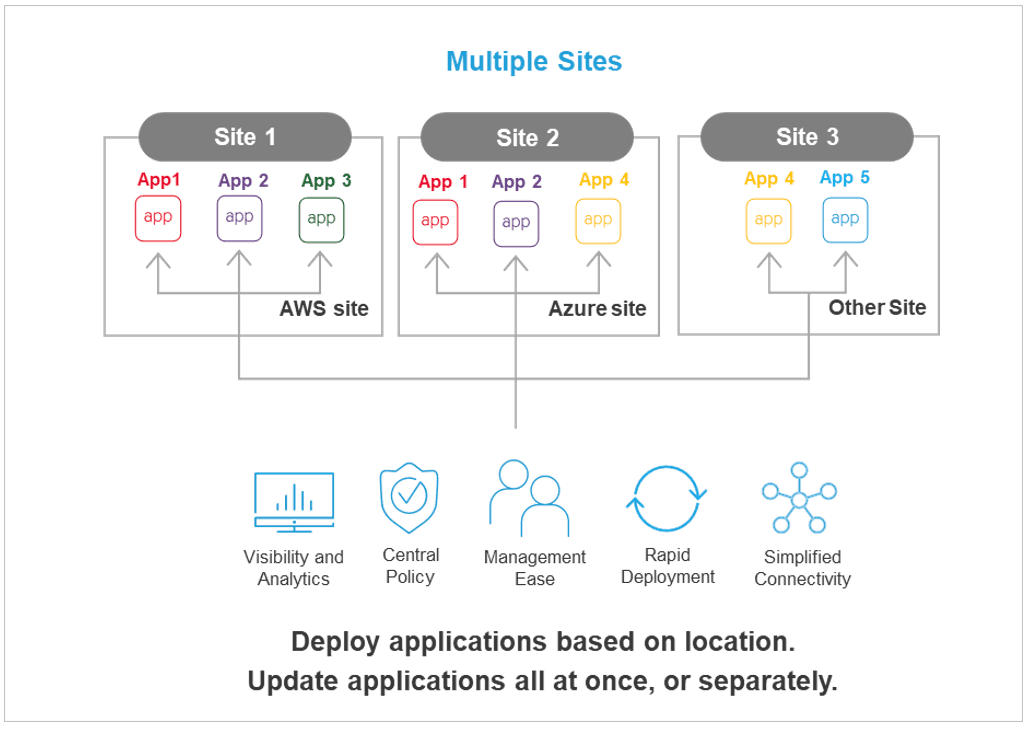
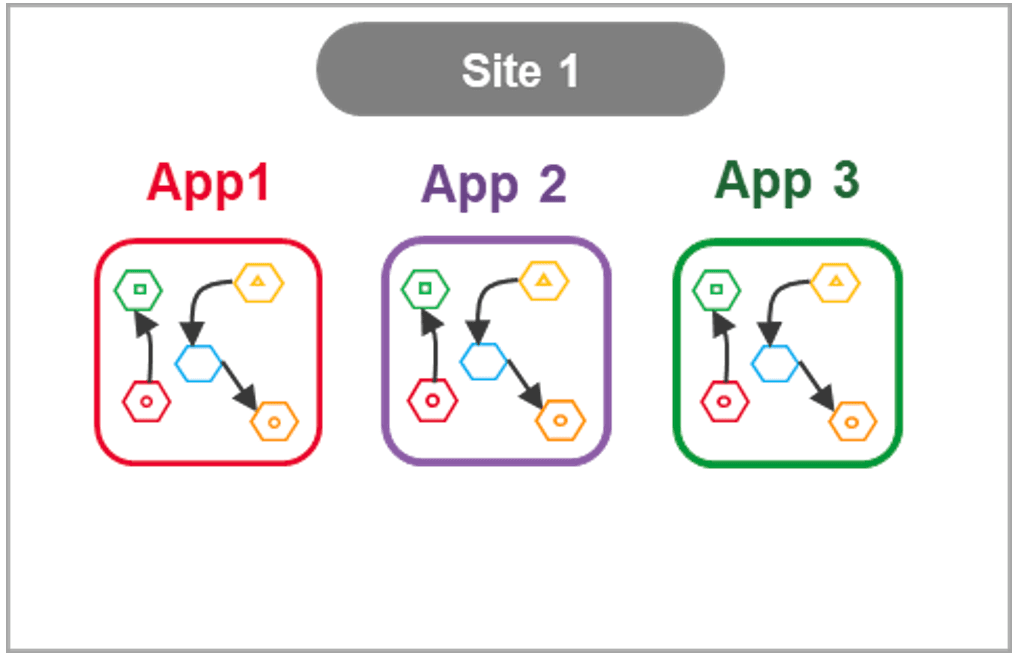
The ability to deploy applications across multiple locations has far reaching ramifications for deployment management and speed. No longer do I need to wrangle bespoke and brittle deployment pipelines, or worry about the nuanced differences of each cloud provider.
I can now deploy applications and get features into the hands of my end users and customers faster by using a standard deployment approach.
Native all the way
The best part is that as a developer I can deploy my application to Kubernetes using native tooling. I can use familiar deployment methodologies and tooling to deploy to multiple clusters. I don’t need anything special on the developer end.
From a deeper technology perspective, this gives me the ability to deploy using both labels, a Kubernetes native construct, to choose one or more sites to deploy to. I can also use Kubernetes native tooling like the kubectl command, and standardised Kubernetes deployment files or manifests. This is a standard way of interacting with Kubernetes. This makes deploying easy, as I can use familiar tooling, with the added benefit of deploying at speed across multiple clusters and locations.
The big thing though is the ability to simply use Kubernetes labels to select whether I am deploying to a single cluster, or multiple clusters. Labels are a Kubernetes native construct that allows me to “tag” an application. I can “tag” or label my application with a location, which can be one or many Kubernetes clusters.
Conclusion
Using F5’s Volterra platform for deploying applications at scale, across multiple locations eases the pain that developers feel on a daily basis. The ability to deploy applications, using Kubernetes native constructs saves time, and gets your application into the hands of the people who need it faster.
The ability to have centralised observability and policy along with easy distributed deployment removes the overhead from developers.
Continuous deployment speed and velocity means getting applications and features into the hands of customers faster.
About the Author
Related Blog Posts

Build a quantum-safe backbone for AI with F5 and NetApp
By deploying F5 and NetApp solutions, enterprises can meet the demands of AI workloads, while preparing for a quantum future.
F5 ADSP Partner Program streamlines adoption of F5 platform
The new F5 ADSP Partner Program creates a dynamic ecosystem that drives growth and success for our partners and customers.

Accelerate Kubernetes and AI workloads with F5 BIG-IP and AWS EKS
The F5 BIG-IP Next for Kubernetes software will soon be available in AWS Marketplace to accelerate managed Kubernetes performance on AWS EKS.

F5 NGINX Gateway Fabric is a certified solution for Red Hat OpenShift
F5 collaborates with Red Hat to deliver a solution that combines the high-performance app delivery of F5 NGINX with Red Hat OpenShift’s enterprise Kubernetes capabilities.
F5 Silverline Mitigates Record-Breaking DDoS Attacks
Malicious attacks are increasing in scale and complexity, threatening to overwhelm and breach the internal resources of businesses globally. Often, these attacks combine high-volume traffic with stealthy, low-and-slow, application-targeted attack techniques, powered by either automated botnets or human-driven tools.
Phishing Attacks Soar 220% During COVID-19 Peak as Cybercriminal Opportunism Intensifies
David Warburton, author of the F5 Labs 2020 Phishing and Fraud Report, describes how fraudsters are adapting to the pandemic and maps out the trends ahead in this video, with summary comments.