在容器领域,声明式配置才是王道

内部的数字化转型对于实现外部的数字化转型至关重要。 内部数字化转型的基础组成部分之一是自动化,它严重依赖于控制平面。 控制平面是实现自动化的地方。 在旧的计算时代,我们将其称为“管理网络”,并使用 SNMP 等协议来提供监控、配置和控制。
今天,管理网络至少在理论上仍然存在,作为我们通过控制平面执行相同任务的媒介。 控制平面是一个混乱的区域,由 API、主节点甚至消息队列组成,使复杂分布式系统中的各个组件能够(几乎)自动进行自我管理。 它越来越多地由事件驱动,这需要改变过去主要依赖命令式管理模型的集中式命令和控制模型的思维。 也就是说,中央系统通过特定的 API 调用隐式地指示组件发生更改。 另一方面,当今的环境依赖于分配改变自身的责任的声明性模型。
在任何系统中,这一点都比在容器化环境中更明显。 从外部来看,这样的系统似乎本质上是流氓系统;消息和事件被随意发布和触发,没有主宰者来指挥谁或什么应该对它们做出反应。 控制平面不再仅仅用于控制,而是跨平面的分布,该平面比老式管理系统的轮毂和辐条架构更像一个网状结构。 在传统世界中,我们使用 API 和协议来推动组件的变化。 在数字化、容器化的世界中,我们使用 API 来提取组件自身更改所需的信息。
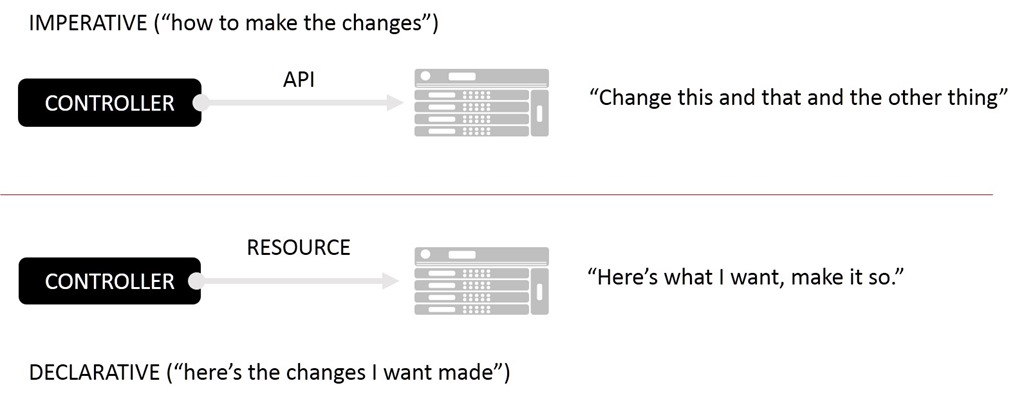
这个新世界是反应性的,它避开了传统控制平面的命令式(API 驱动)模型,而是依靠更开放、声明式的模型来实现所需的自动化最终状态。
这并不奇怪。 随着我们越来越多地采用软件驱动的方法(在 DevOps、Cloud 和 NFV 的指导下),我们必须同时处理大规模的运营规模。 由于所有变更的负担都落在中央控制器上,该控制器能够通过令人困惑的 API 阵列与几乎无限的组件组进行通信,因此中心辐射式、命令式的管理模型无法有效扩展。 这是一个“推送”模型,其中管理器(控制器)将更改推送到每个受影响的组件。 它成为决定整个系统成败的瓶颈。
依赖于组件拉动的事件驱动模型对于扩展和减轻控制器的负担是必要的,这反过来又要求希望参与该控制平面的组件能够适应声明性配置模型。 因为容器不是通过 API(命令式)来推送更改,而是推动我们通过声明式配置来提取更改。 组件提供商(无论是开源还是商业)有责任正确订阅更改,然后立即提取实施该更改所需的适当信息。
如果这听起来像是基础设施即代码,那它就应该是。 声明性配置基本上是代码,或者至少是代码工件。 自动化越来越依赖于将配置与服务分离的前提。 在理想的乌托邦模型中,这些声明性配置是完全不可知的。 也就是说,任何支持该服务的供应商(商业或开源)的任何产品都可以读取它们。 例如,描述适当服务(虚拟服务器)及其资源池的应用程序的声明性配置将能够被服务 X 或服务 Y 提取和实施。
Kubernetes 资源文件是声明式配置模型的一个很好的例子,其中描述了所需的内容,但没有规定如何操作。 这与依赖基础设施 API 的系统有显著不同,后者要求实现者熟悉(有时甚至非常熟悉)如何实现所需的结果。
声明式模型也使得我们能够像对待牛一样对待基础设施。 如果一个实例失败了,那么终止它并启动一个新实例是很简单的事情。 它所需的所有配置都在资源文件中;没有“保存您的工作否则将会丢失”按钮,因为没有什么工作可丢失。 这几乎是不可变的,而且绝对是一次性的基础设施,并且在每分钟甚至每秒都在变化的系统中,它是必需的,以最大限度地减少故障的影响。
随着我们越来越多地走向自动化的规模化系统和——我敢说吗?——安全性,我们将需要采用声明性模型来管理组成应用数据路径的无数设备和服务,否则可能会被手动集成和自动化方法产生的大量运营债务所淹没。