
Data orchestration
Data orchestration automates movement, transformation, and governance of data across complex data and AI pipelines.
Data orchestration refers to the automated coordination, transformation, and movement of data across systems, pipelines, and environments. It ensures that data is collected, standardized, governed, and delivered reliably to analytics, applications, and AI workloads.
What is data orchestration?
Data orchestration oversees the entire data lifecycle, from ingestion and transformation to activation and delivery across data lakes, warehouses, operational systems, and AI pipelines. It automates workflows that replace manual handoffs and siloed scripts, ensuring data remains accurate, timely, and consistently formatted in distributed environments.
Data orchestration vs data integration vs ETL
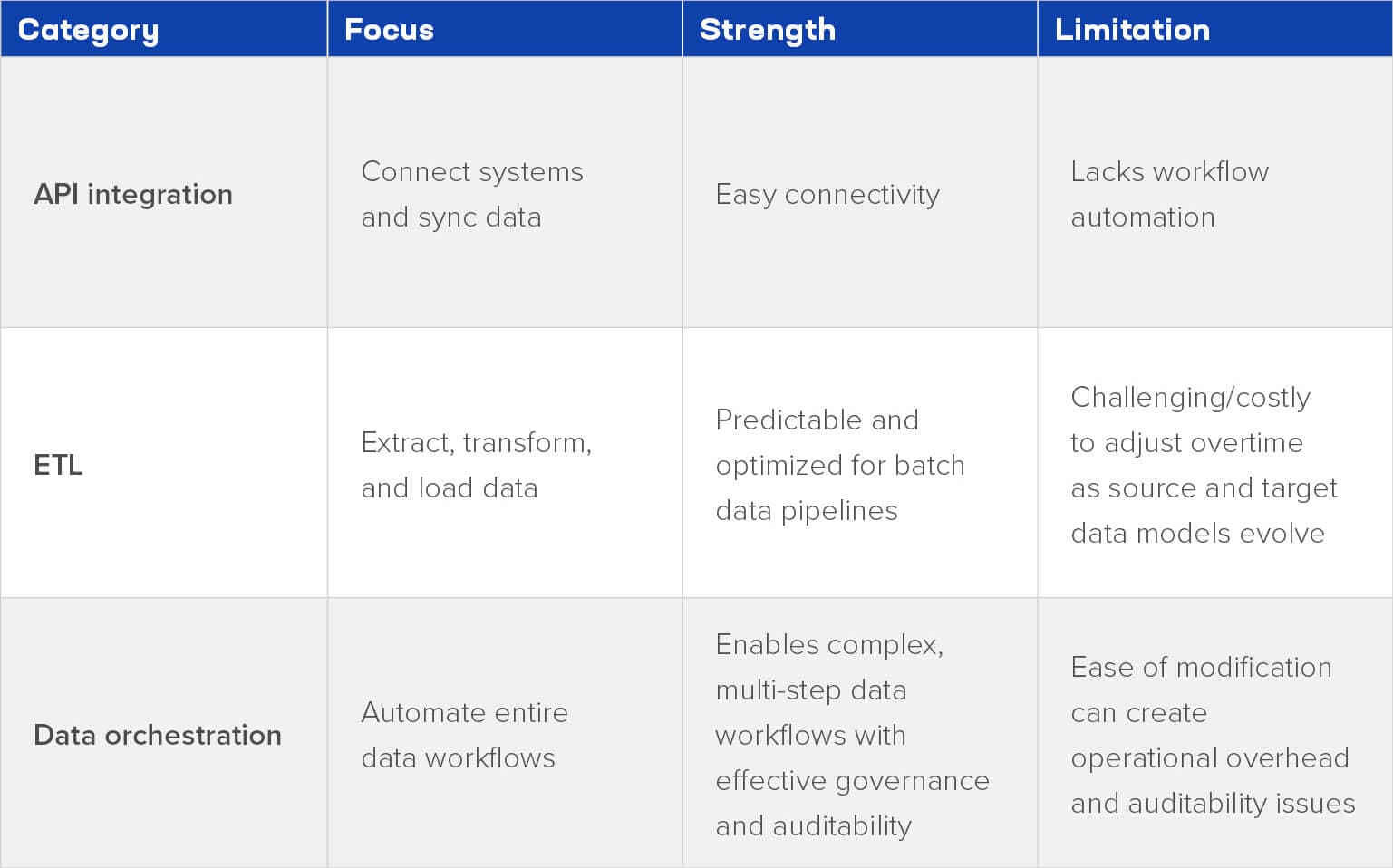
Data integration combines data from multiple sources but typically focuses on connectivity. ETL tools extract, transform, and load data into target systems, often in batch mode.
Data orchestration coordinates all data workflows, including batch, streaming, multicloud, analytics, and AI, ensuring they run in the right order with quality, governance, and monitoring.
Modern data stacks rely on data orchestration
As organizations expand into multicloud deployments, real-time analytics, and AI-driven applications, the volume and speed of data exceed the capacity of manual processes. Data orchestration ensures that pipelines continuously deliver high-quality, governed data to downstream systems to process.
AI orchestration builds on data orchestration
Data orchestration is foundational to data management; it encompasses data workflows, data collection, data cleaning, and moving usable data. AI orchestration expands data orchestration to cover the entire machine learning (ML) lifecycle, including coordinating feature pipelines (specifically structured for predictions), model training (resource scheduling and dataset management), model deployment, monitoring model drift and accuracy, and feedback loops for retraining or tuning.
Why is data orchestration important?
Data orchestration provides several benefits for enterprises:
- Improves data reliability and quality: Standardizes data across sources, enforces governance policies, and ensures consistent delivery to analytics and AI systems.
- Accelerates data and AI pipelines: Automates workflow sequencing and error handling, reducing manual engineering overhead.
- Supports real-time insights: Natively supports streaming and event-based workflows, enabling rapid decision-making.
- Strengthens governance and compliance: Uses metadata for tracking (sources, modifications and progress), lineage (audit trails), and access controls (enforcement) to help teams meet regulatory and security requirements.
- Scales with multicloud and hybrid environments: Orchestrates data across distributed architectures without traditional fragile point-to-point legacy system integrations.
How does data orchestration work?
Data orchestration typically follows four stages:
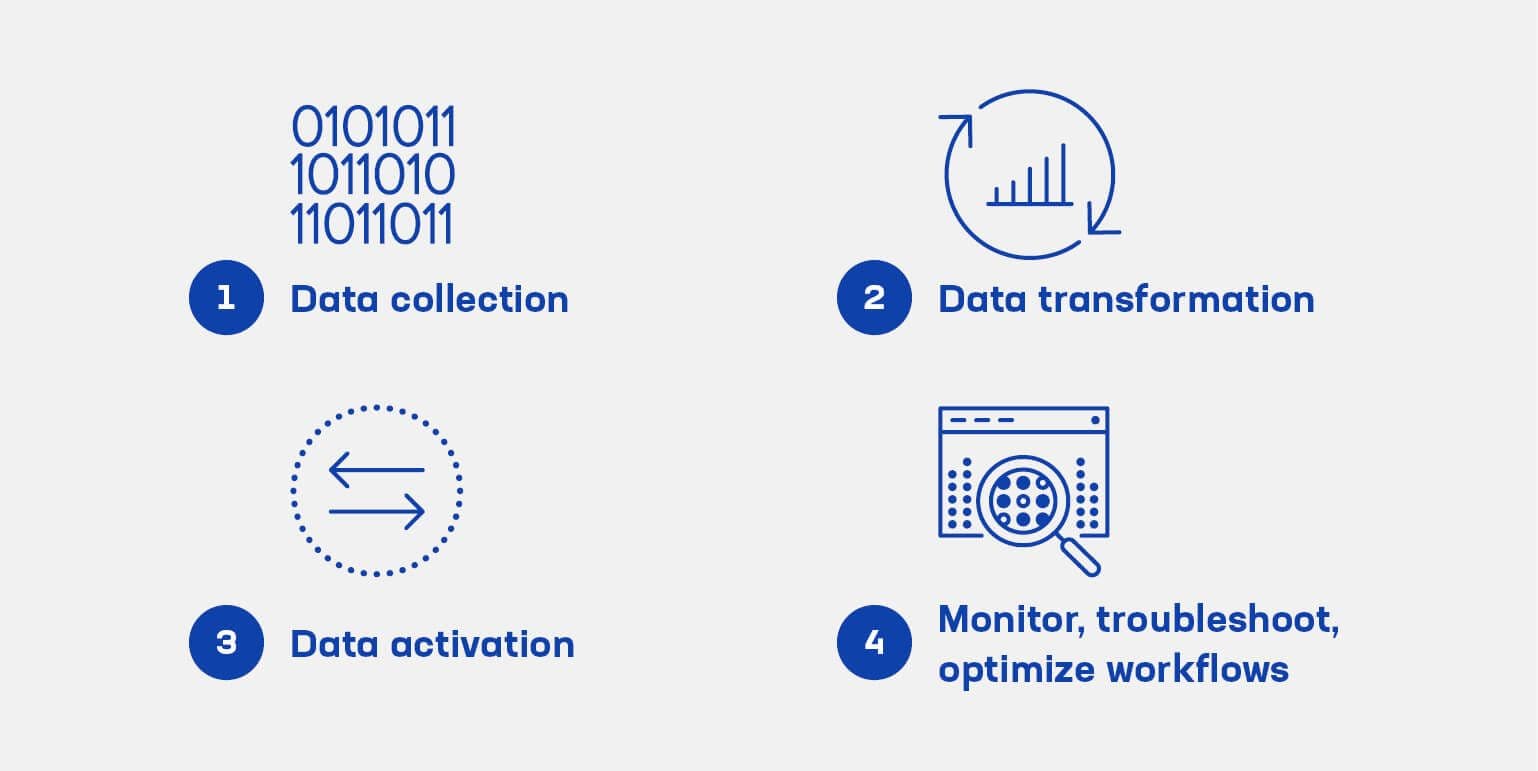
1. Ingest and collect data: Connects to databases, SaaS systems, logs, APIs, IoT devices, and streaming platforms.
2. Transform and standardize data: Applies schema validation, cleanup, normalization, enrichment, and quality checks to data.
3. Activate and deliver data: Routes refined data to data lakes, warehouses, BI tools, operational systems, and AI/ML pipelines.
4. Monitor, troubleshoot, and optimize workflows: Tracks performance, lineage, data freshness, and pipeline health.
Key components of a data orchestration system include:
- Workflow engine for pipeline sequencing
- Connectors and integration frameworks
- Metadata management and lineage
- Quality checks and policy enforcement
- Observability and logging
- Error handling and retries
How does F5 handle data orchestration?
F5 enables organizations to operate orchestrated data and AI pipelines securely, reliably, and at scale by strengthening the underlying traffic, APIs, and observability fabric on which these pipelines depend.
Secure and governed data delivery: AI data pipelines rely on APIs, services, and distributed storage systems. F5 protects these paths with inline inspection, API governance, role-based access control (RBAC), and encrypted traffic management, ensuring sensitive data moves safely and securely across hybrid and multicloud environments.
Optimized, high-performance connectivity: Data orchestration often spans multiple networks, clouds, and applications. The F5 Application Delivery and Security Platform (ADSP) delivers high-bandwidth routing, load balancing, and performance optimization to minimize latency and prevent bottlenecks across pipelines.
AI governance and model-aware protection: F5 AI Guardrails enforces real-time policy controls by monitoring requests, responses, and data flows between applications and AI models. It prevents data leakage, blocks unsafe traffic, and ensures only compliant interactions are permitted.
Unified visibility for data and AI pipelines: F5 AI Assistant delivers cross-environment observability, analyzing logs, lineage, telemetry, and policy data to identify bottlenecks and performance issues across distributed pipelines.
Benefits of implementing data orchestration
Data orchestration delivers major operational and strategic advantages:
- Efficiency: Automates repetitive manual data engineering tasks, such as ingestion, transformation, and pipeline scheduling, reducing effort and freeing teams to focus on other functions like analytics and development.
- Speed: Ensures data flows continuously across systems, supporting real-time analytics, high-velocity pipelines, and faster access to essential insights for business and AI workloads.
- Reliability: Enforces schema consistency, quality checks, and automated retry logic. This reduces data errors, pipeline problems, and downstream disruptions that impact analytics and model performance.
- Scalability: Provides a unified orchestration layer capable of coordinating hundreds or thousands of pipelines across hybrid and multicloud environments. As data volume and velocity grow, orchestration ensures predictable pipeline performance.
Data orchestration use cases for businesses
Enterprises apply data orchestration across a wide range of operational and analytical workflows:
- Real-time analytics and dashboards: Coordinating streaming data from applications, IOT sensors, and transactions to provide instant insights
- Customer and personalization platforms: Aggregate data from CRM, web interactions, support systems, and marketing tools to deliver unified customer profile data.
- Fraud detection and risk scoring: Synchronizes event logs, transactions, user behavior, and third-party data into near real-time detection models.
- Supply chain visibility and optimization: Orchestrates data from logistics systems, inventory databases, and IoT devices for forecasting and route optimization.
- AI/ML feature pipelines: Formulate, confirm, and move data to training and inference environments as part of ML workflows.
- Regulatory reporting: Automates compliant data preparation for audit, financial reports, and other industry regulatory submissions.
Role of data orchestration in data governance
Data orchestration strengthens governance by embedding controls directly into the data lifecycle:
- Lineage: Tracks the full path of data from the source system through all transformation steps, providing visibility essential for auditing, debugging, and investigating model results.
- Access control: Enforces permissions, RBAC, and least-privilege rules across pipelines, ensuring users and systems interact only with the data they’re authorized to access.
- Audit trails: Maintains verbose logs of data movement, transformations, approvals, and policies, enabling clear accountability and compliance certification.
- Support for privacy regulations: Automates checks such as data masking, tokenization, PII deletion requests (e.g., GDPR), and retention policies. Orchestration ensures sensitive data is handled consistently across all pipelines and systems.
Definition and scope of AI orchestration
AI orchestration involves the oversight, management, and automation of all elements used in developing, deploying, and maintaining ML and AI systems. It extends data orchestration across the whole AI lifecycle by handling feature pipelines, training processes, model packaging, deployment, monitoring, and improvement.
AI orchestration covers ML operations (MLOps) workflows, model governance, operational observability, infrastructure readiness, and policy enforcement across hybrid and multicloud environments.
Key components of an AI orchestration system
AI orchestration systems standardize and automate each stage of the ML lifecycle:
- Data and feature pipelines: Prepare, validate, and deliver data features (quality and current data) to training and inference environments.
- Training orchestration: Schedules training jobs, configures compute resources (GPU/CPU), manages distributed training environment scheduling, and tracks model training.
- Model deployment: Automates model packaging, versioning, test rollouts, deployments, and routing supporting real-time inference.
- Monitoring and performance analysis: Tracks model drift, accuracy, latency, resource usage, and changes to input data to ensure production reliability.
- Feedback loops: Captures predictions, outcomes, user interactions, and model telemetry to support retraining, tuning, and continuous learning.
Key benefits of implementing AI orchestration
AI orchestration simplifies and strengthens enterprise AI operations:
- Repeatable AI delivery: Standardized workflows reduce ad-hoc scripts and manual processes, making AI development and deployment consistent and predictable, removing manual errors.
- Governed AI operations: Provides visibility into model lineage, approvals, data consumption, and versioning to ensure responsible and compliant AI conduct.
- Reliable, production-ready pipelines: Ensure models run with consistent performance, suitable latency, and automated monitoring to prevent failures.
- Faster iteration cycles: Streamlines retraining, validation, and deployment, accelerating innovation and shortening time-to-value for AI features.
- Scalable multi-model operations: Coordinates workloads across differing clouds, edge locations, and compute environments, supporting AI portfolios.
AI orchestration platforms vs. generic workflow automation
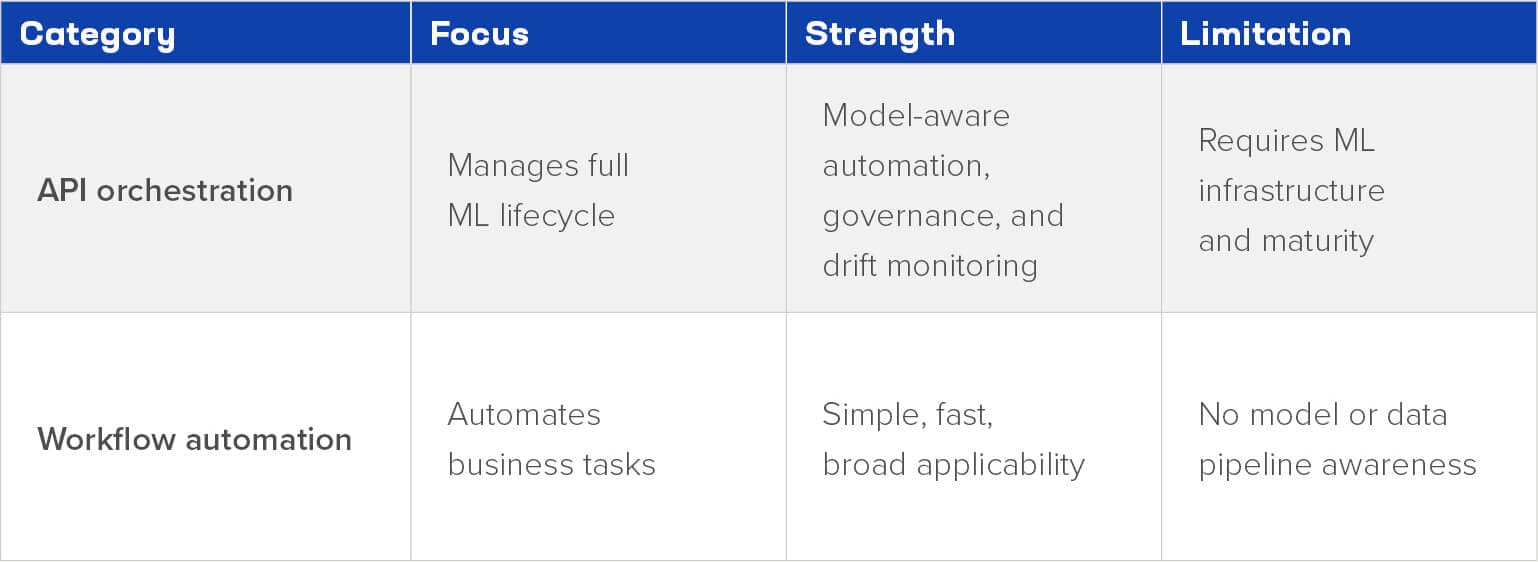
AI orchestration platforms are purpose-built for ML and GenAI; they understand model lifecycle requirements, provide model-specific monitoring, support distributed training, and enforce security and compliance for AI.
Capabilities typically include:
- Feature store integration
- Model lineage and versioning
- GPU/accelerator scheduling
- Drift detection and automated retraining
- Policy and governance controls
- Inference traffic management
Generic workflow automation, on the other hand, encompasses traditional workflow engines (e.g., Business Process Management, schedulers, etc.) that automate business processes but lack ML capabilities. They do not track training, monitor model drift, manage GPU infrastructure, or enforce model-specific governance.
AI orchestration use cases in business and impact on digital transformation
Enterprises use AI orchestration to scale AI programs beyond proof-of-concept:
- Automated model deployment across business units: Supports consistent rollout of solutions using fraud models, pricing engines, or demand-forecasting models.
- Real-time personalization and recommendations: Manages data ingestion, training updates, and inference endpoints to deliver scaled individualized experiences.
- Predictive maintenance and IoT analytics: Manages streaming data and inference pipelines that can detect anomalies, predict failures, and optimize performance.
- Conversational AI and generative applications: Orchestrates databases, retrieval pipelines, prompt governance, and model services to support customer operations.
- Enterprise AI transformation: AI orchestration lays the foundation for repeatable, compliant, and governed AI workflows, allowing organizations to operationalize AI across business processes, not just in isolated systems.
Governance and compliance in AI orchestration
AI orchestration embeds governance directly into model operations, ensuring enterprise AI remains safe, accountable, and compliant.
- Tracking data: Monitors datasets, features, transformations, and data sources to prevent unauthorized use and maintain trackability for audits.
- Tracking models: Captures model versions, training data, configurations, performance, approvals, and deployment history, providing transparency and regulatory compliance.
- Tracking decisions: Logs inference outputs, explanations, and decisions, enabling a complete review of model impact, bias, and fairness.
- Policy and access controls: Apply role-based permissions, data masking, and API governance to ensure only authorized systems and users can interact with models or sensitive data.
- Regulatory readiness: Supports compliance with AI-focused regulations (e.g., European Union Artificial Intelligence Act (EU AI Act), National Institute of Standards and Technology Artificial Intelligence Risk Management Framework (NIST AI RMF), or industry-specific regulations) by ensuring auditability and traceability throughout the AI lifecycle.
Data orchestration | FAQ
What is data orchestration, and how does it work, step by step?
Data orchestration automates the movement, transformation, and delivery of data across distributed systems. It typically follows four steps:
- Ingest and collect data from databases, SaaS apps, logs, streaming services, and APIs.
- Transform and standardize data using validation, normalization, enrichment, and formatting rules.
- Activate and deliver data to warehouses, lakes, applications, analytics platforms, and ML systems.
- Monitor and optimize pipelines by tracking freshness, quality, lineage, and operational health.
How is data orchestration different from data integration and ETL tools?
Data integration connects systems; ETL tools extract, transform, and load data, often in batches. Data orchestration manages these workflows across batch, streaming, cloud, and AI environments, ensuring reliable pipelines with proper governance, quality checks, and monitoring.
What are the key components of a data orchestration system?
A typical orchestration platform includes:
- Workflow engine for scheduling and dependency management
- Connectors and integration frameworks for ingestion
- Metadata and lineage solutions to track data
- Quality validation and policy enforcement
- Observability and logging for pipeline performance
- Error handling and retry logic
What are the main benefits and use cases of data orchestration for businesses?
Benefits include greater efficiency, faster insights, improved reliability, and scalability across hybrid environments. Use cases include real-time dashboards, customer systems, fraud detection, supply chain analytics, regulatory reporting, and AI/ML training pipelines.
What is AI orchestration, and how does it relate to data orchestration and MLOps?
AI orchestration manages the entire machine learning lifecycle, including data prep, training, deployment, monitoring, and improvement, by coordinating components that convert data into models and models into production. It works with MLOps to enhance governance, automation, and lifecycle tracking.
What are common tools and platforms for data and AI orchestration?
Standard data orchestration tools include Apache Airflow, Dagster, Prefect, and cloud-native schedulers. AI orchestration platforms include MLflow, Kubeflow, Vertex AI Pipelines, SageMaker Pipelines, Databricks Workflows, and specialized MLOps solutions. Most enterprises use a combination that aligns with their data stack, cloud provider, and/or model strategy.
What are the biggest challenges in implementing AI orchestration, and how can teams address them?
Challenges include fragmented data, inconsistent training, lack of lineage visibility, manual deployment, model drift and bias, and compliance issues. Teams can address these by adopting standardized pipelines, implementing lineage and observability tools, automating deployment, enforcing governance policies, and monitoring throughout the lifecycle.
How do data and AI orchestration support governance and compliance?
They embed governance into workflows by tracking data lineage, access controls, data transformations, audit trails, and validation of model data use. In AI orchestration, this includes tracking model versions, data, decisions, and performance to support transparency and compliance.
Where should enterprises start if they are new to data and AI orchestration?
Organizations should start with a few high-impact pipelines, like key features or analytics workflows, then expand. Establishing centralized metadata, lineage, and quality controls early reduces complexity. Teams should also assess orchestration tools that align with their cloud strategy and adopt scalable governance frameworks for data and AI workloads.
How F5 helps
Data and AI orchestration are vital for modern strategies, ensuring reliable, automated pipelines as enterprises expand real-time analytics, deploy larger models, and use multicloud environments. It guarantees proper data flow, high-quality inputs, and consistent AI behavior. Success depends on strong infrastructure, including data networks, security, and delivery tech. Without resilient traffic, secure endpoints, and visibility, even advanced platforms struggle under load.
Orchestration relies on a solid foundation. Resilient traffic management enables scalable data and model services. API security ensures governance and protects sensitive data. Unified observability offers cross-environment insights into performance, drift, errors, and behavior, helping teams operate pipelines confidently.
Enterprises should ask: Are pipelines reliable under load? Is governance consistent? Can issues be traced across clouds? Are networking, security, and delivery teams aligned with data and AI? If answers are “no” or “not sure,” consider rethinking orchestration and infrastructure as a unified system.
Learn more at f5.com.